Introducing the Retailgrid price optimization engine
Our new price optimization engine runs six elasticity tiers in one pass, auto-selects the most confident, and only moves a price as far as the data allows.
Most price optimization software has the same failure mode. It hands a category manager a number, asks them to trust it, and offers no way to check the working. So the number sits in a spreadsheet, unused, while the team prices the way they always have. The model was never wrong about the math - it was wrong about what makes a recommendation get applied.
Today we are shipping the Retailgrid price optimization engine: the demand and elasticity core that powers every recommendation in the platform. It was built around a single idea - a price recommendation is only worth as much as your confidence in it. The engine measures that confidence explicitly, shows its reasoning, and only moves a price as far as the evidence allows.
Here is what is new, and why each part matters if you actually have to defend a price.
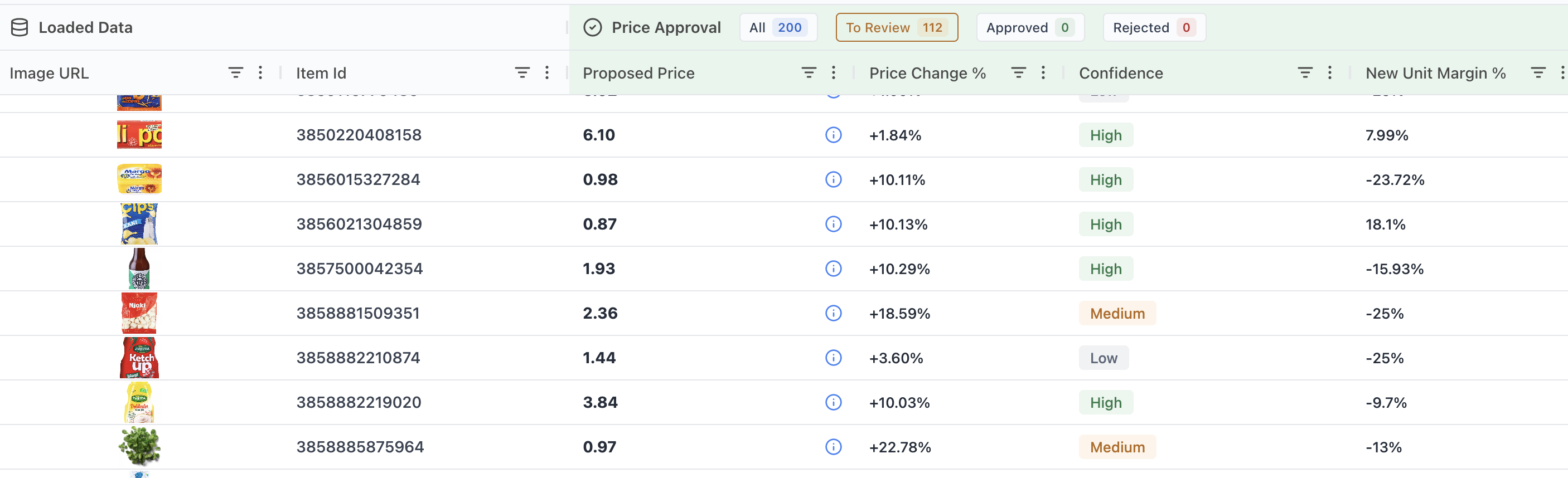
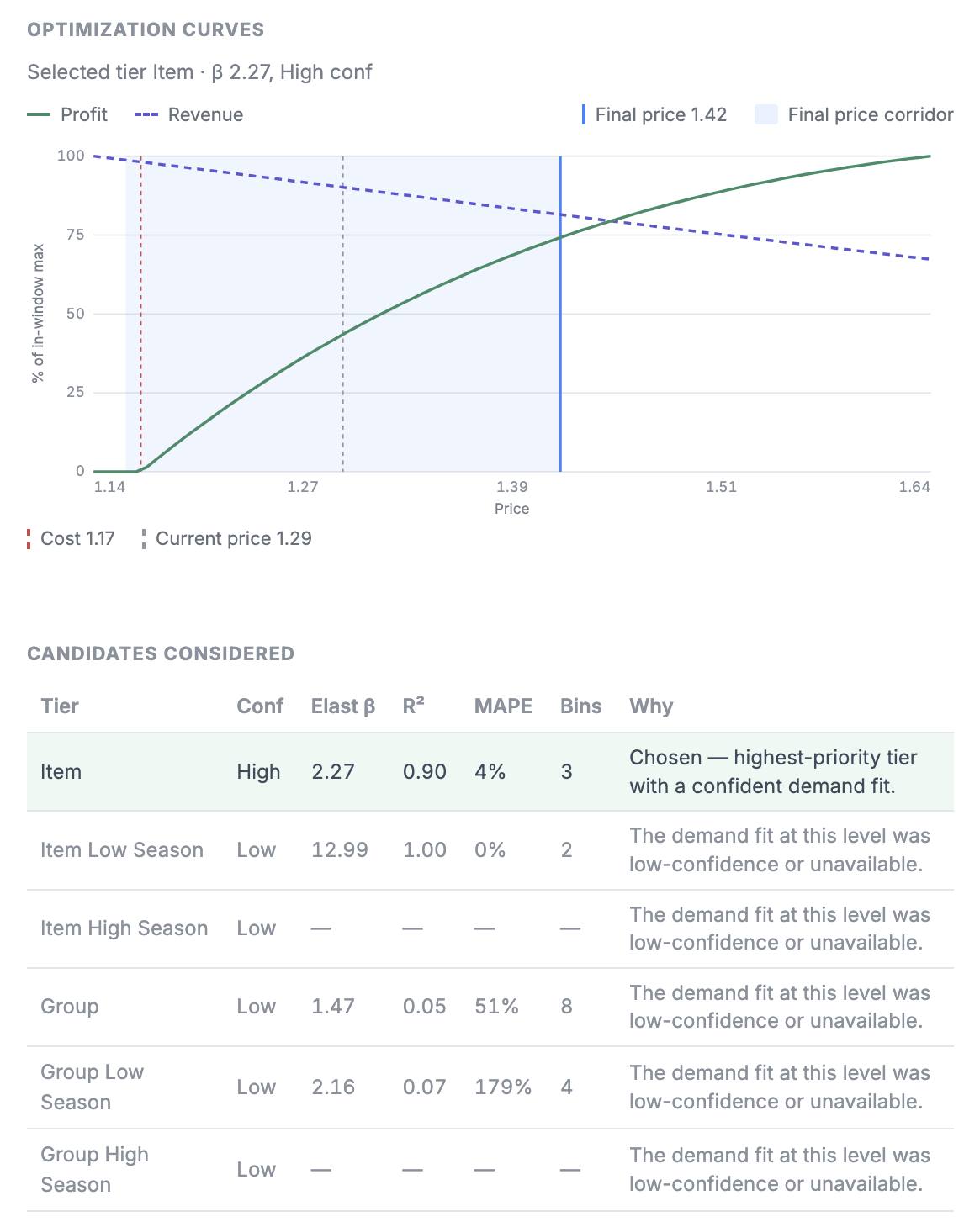
Six elasticity tiers in one run, the most confident one wins
Price elasticity is never measured cleanly. The same SKU can be estimated at the item level, grouped with similar items, rolled up to a subcategory, or modeled from category-wide behavior - and each level trades precision for stability. Estimate too narrowly and thin data gives you noise. Estimate too broadly and you lose the signal that makes the SKU specific.
Instead of forcing one choice up front, the engine calculates six elasticity tiers for every product in a single run - from the most granular item-level fit up to the broadest aggregation - and then auto-selects the tier with the highest statistical confidence for that SKU. A fast-moving hero product with years of clean transactions resolves at the sharpest tier. A long-tail item with a handful of sales falls back to a tier that still holds up. You do not configure this per product. The engine picks the level the data can actually support and tells you which one it used.
Thin-data SKUs get clustered, not guessed
Every assortment has a long tail of products that barely sell - new arrivals, niche variants, slow seasonal lines. Classic optimization either skips them or invents an elasticity from almost nothing. Neither is acceptable when those SKUs still tie up cash and shelf space.
For low-sales SKUs, the engine builds clusters automatically from product attributes and demand levels, grouping each thin item with the products that behave most like it. A new SKU with no price history inherits a defensible demand response from its cluster rather than a number pulled out of thin air. As real sales accumulate, the same item graduates to its own tier. The result is coverage across the full catalog - not just the top sellers - without pretending to a precision the data does not have.
Confidence decides how far a price moves
This is the part that keeps the engine honest. Confidence is not just a label printed next to a recommendation - it governs how aggressively the engine acts. High confidence earns a larger, decisive move. Low confidence earns a small, cautious one, or none at all. No confidence, no risky decision.
It is the opposite of how black-box optimizers behave, where a shaky estimate and a rock-solid one produce equally bold price changes and you have no way to tell them apart. Here, the size of the move is tied to the strength of the evidence behind it. That single rule is why the recommendations are safe to automate: you can let high-confidence SKUs reprice on their own and route the uncertain ones to a human, because the engine has already throttled its own aggressiveness on exactly those items.
Built to run on billions of transactions
An elasticity method that works on a clean demo catalog and falls over on a real assortment is not much use. The engine is built to run on billions of transactions and millions of products, so it can model an entire chain's history rather than a sampled slice. That scale matters for the long tail specifically - the clustering and tiered fallback only pay off when the engine has seen enough of the catalog to know which products genuinely resemble each other.
Open parameters, not a black box
Over half of enterprise teams cite the lack of explainability as a barrier to scaling AI, according to IBM's Global AI Adoption Index - and pricing is where that barrier bites hardest, because someone has to stand behind the number in front of a CFO. The engine is self-explainable by design. The model parameters are open for review: the chosen elasticity tier, the confidence score, the cluster a thin SKU borrowed from, and the demand factors that shaped the curve are all visible, not hidden behind a score you have to take on faith.
That means a category manager can interrogate any recommendation, a finance partner can audit the logic, and a data team can sanity-check the fit. Explainability is not a report you generate after the fact. It is the same set of parameters the engine optimized on, exposed for you to read.
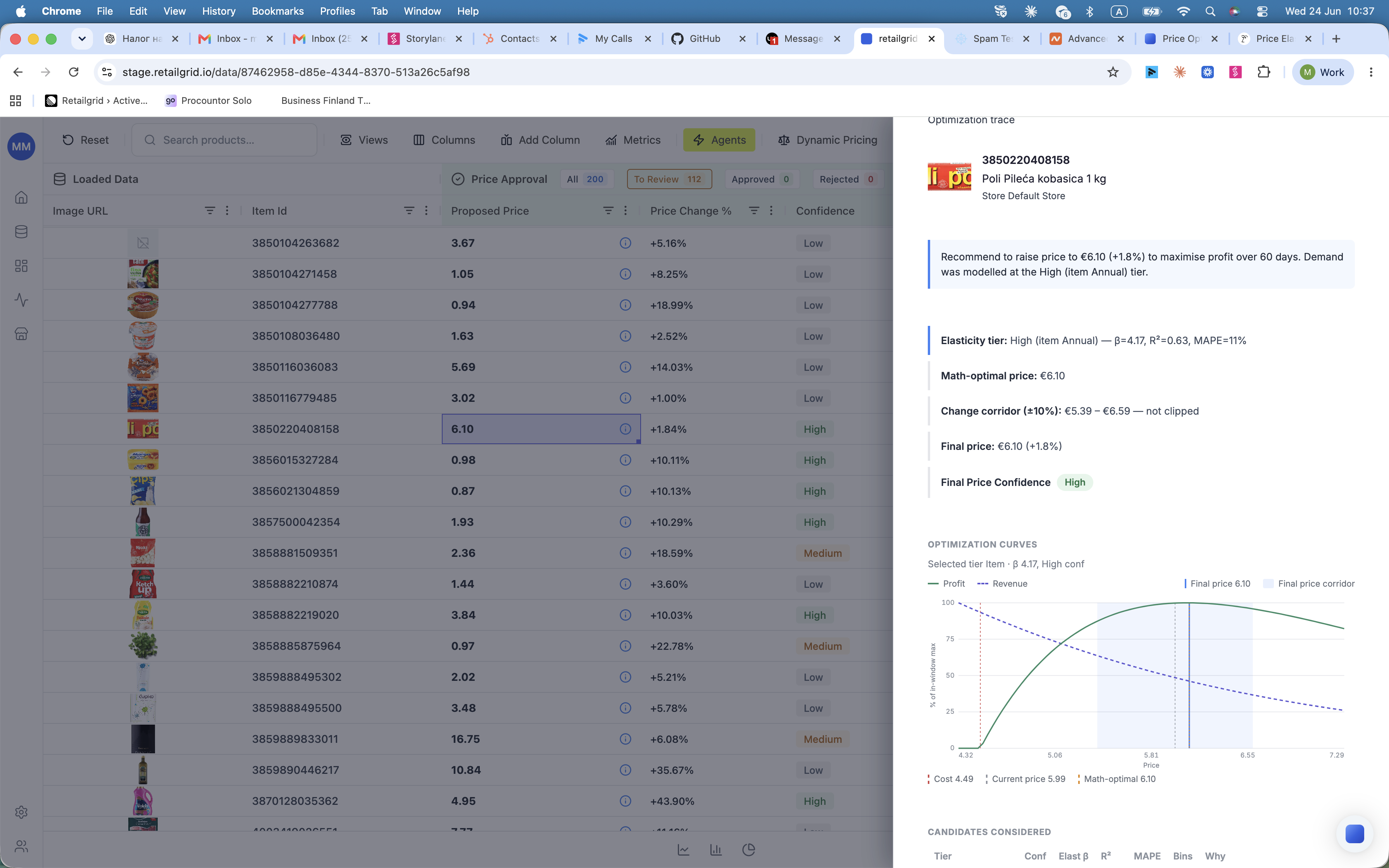
The demand factors behind every recommendation
A price is only as good as the demand picture behind it, and demand is never just a function of price. The engine analyzes a broad and growing set of factors for each SKU, including underlying demand and trend, price elasticity, seasonality, sales anomalies, competitor price changes, cannibalization between substitute products, and halo effects across complements. When a markdown on one SKU pulls demand from its sibling, or a promotion lifts the whole bundle around it, the engine accounts for it rather than treating each product as an island.
That list is not fixed. We are extending the factor set continuously, and because the parameters are open, you can always see which signals shaped a given recommendation and how much each one moved the curve.
Where the price optimization engine fits
The engine does not replace your pricing team or your business rules. It produces the demand and elasticity backbone; your margin floors, competitor corridors, KVI locks, and rounding rules still sit on top of every recommendation, and optimization never ships a price outside the boundaries you set. What changes is the quality of the proposal underneath those guardrails - and, just as important, your ability to see why it is what it is.
For retailers carrying real inventory, that has a direct cost angle. Carrying stock runs a widely cited 20-30% of its value per year once you account for capital, space, and obsolescence, so a recommendation that balances margin against inventory return - and that you can actually trust enough to apply - is worth far more than a bolder number nobody acts on.
The price optimization engine is live across the Retailgrid platform now. If you want to see it run on your own category data - the tiers, the confidence scores, and the reasoning behind every price - take a look at how it works or book a 20-minute walkthrough.